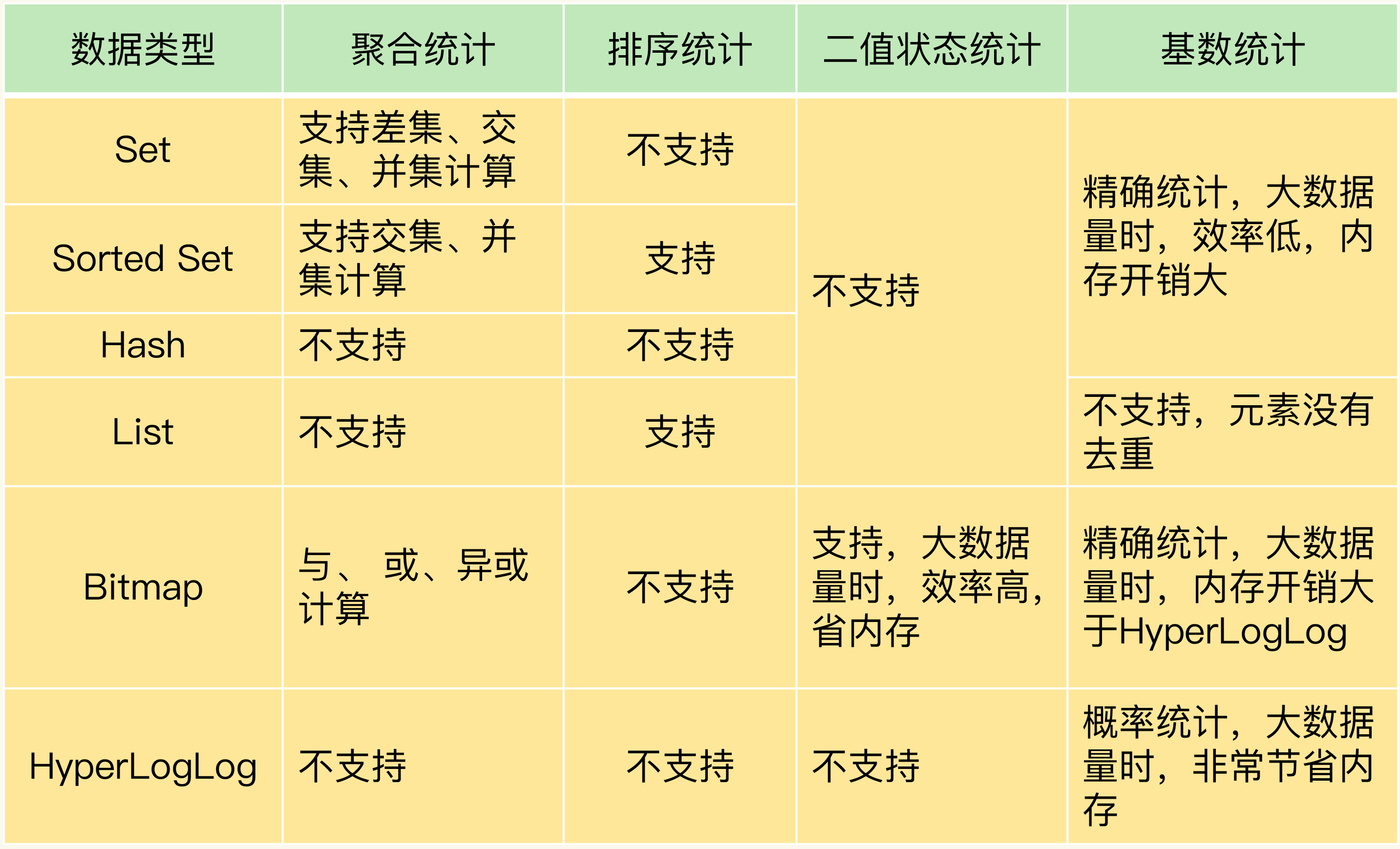
集合类型常见的四种统计模式
- 聚合统计
- 排序统计
- 二值状态统计
- 基数统计
聚合统计
- 交集
- 并集
- 差集
举例:每天的新增用户数和第二天的留存用户数
- 一个集合记录所有登录过 App 的用户 ID
- 一个集合记录每一天登录过 App 的用户 ID
- key = user:id:日期
- value = 用户id(Set类型)
排序统计
在面对需要展示最新列表、排行榜等场景时,如果数据更新频繁或者需要分页显示,建议你优先考虑使用 Sorted Set
二值状态统计
二值状态就是指集合元素的取值就只有 0 和 1 两种
- 在签到打卡的场景中,我们只用记录签到(1)或未签到(0),所以它就是非常典型的二值状态
- 再如:商品有没有、用户在不在
- 在记录海量数据时,Bitmap 能够有效地节省内存空间。
Bitmap
Bitmap 本身是用 String 类型作为底层数据结构实现的一种统计二值状态的数据类型。String 类型是会保存为二进制的字节数组,所以,Redis 就把字节数组的每个 bit 位利用起来,用来表示一个元素的二值状态。你可以把 Bitmap 看作是一个 bit 数组。
举例:统计 1 亿个用户连续 10 天的签到情况
- 每天的日期作为 key,每个 key 对应一个 1 亿位的 Bitmap,每一个 bit 对应一个用户当天的签到情况。
- 对 10 个 Bitmap 做“与”操作,得到的结果也是一个 Bitmap
- 在这个 Bitmap 中,只有 10 天都签到的用户对应的 bit 位上的值才会是 1
- 用 BITCOUNT 统计下 Bitmap 中的 1 的个数,这就是连续签到 10 天的用户总数了
内存开销
- 每天使用 1 个 1 亿位的 Bitmap,大约占 12MB 的内存(10^8/8/1024/1024)
- 10 天的 Bitmap 的内存开销约为 120MB
基数统计
基数统计就是指统计一个集合中不重复的元素个数
- Set
- HyperLogLog:当数据量大到 Set 搞不定时用
- 用于统计基数的数据集合类型
- 最大优势就在于,当集合元素数量非常多时,它计算基数所需的空间总是固定的,而且还很小
- 在 Redis 中,每个 HyperLogLog 只需要花费 12 KB 内存,就可以计算接近 2^64 个元素的基数
- HyperLogLog 的统计规则是基于概率完成的,标准误算率是 0.81%
- 例如:HyperLogLog 统计的 UV 是 100 万,但实际的 UV 可能是 101 万
小结
Redis 中大数据解决方案
Bitmap
- 统计 1 亿个用户连续 10 天的签到情况
- 每天使用 1 个 1 亿位的 Bitmap,大约占 12MB 的内存(10^8/8/1024/1024)
- 10 天的 Bitmap 的内存开销约为 120MB
HyperLogLog
- 统计2^64 个元素的基数,花费 12 KB 内存
- 基于概率完成,标准误算率是 0.81%